
Implementare correttamente il tag canonical è essenziale per ottimizzare la gestione del tuo sito web. Evita infatti che i motori di ricerca disperdano la loro "autorevolezza" tra pagine duplicate dello stesso contenuto. Scoprirai come consolidare la SEO su un URL preferito, migliorando e proteggendo il posizionamento.
Cos'è il tag canonical e come funziona per la SEO
Il tag canonical consente di indicare la versione di riferimento – quella canonica – di una pagina web. Segnala infatti ai crawler quale URL indicizzare, prevenendo così problemi legati a contenuti duplicati. Inserito nell'intestazione (header) della pagina, evita che l'autorità venga dispersa fra pagine simili.

URL canonico: definizione e ruolo nell'indicizzazione
Comprendere cos’è un URL canonico è fondamentale per definire quale versione di una pagina principale debba essere indicizzata. Se utilizzi un CMS, strumenti automatizzati come il canonical tag in WordPress facilitano l’adozione corretta di questo tag. Attraverso l’elemento link rel stabilisci in modo proattivo la versione canonica, invece di lasciare che Google scelga in modo autonomo – e potenzialmente erroneo – quale pagina considerare.
- Consolidamento dell'autorità: il tag canonical concentra il link juice e i segnali di posizionamento su un’unica pagina canonica, proteggendo il ranking da eventuali contenuti duplicati e URL duplicati.
- Riduzione del crawl budget: indirizzando l’attenzione dei crawler verso la versione canonica, si evitano scansioni ridondanti verso contenuti ripetuti, con conseguente risparmio di risorse.
- Indicizzazione controllata: in assenza di un elemento link esplicito, i motori di ricerca potrebbero indicizzare la versione errata della pagina, compromettendo la tua visibilità organica.
- Prevenzione dei contenuti duplicati: definire un URL canonico ti protegge da potenziali penalizzazioni, riunendo tutto il contenuto duplicato attorno a una singola pagina di riferimento.
Sebbene Google tratti questo tag come un forte suggerimento, in alcuni casi potrebbe ignorarlo se trova incongruenze. Effettuare un'analisi tecnica con uno strumento dedicato, come un audit SEO, permette di verificare che la sua implementazione sia corretta ed evidenziare eventuali errori critici. Per questo motivo si consiglia di affiancarlo ad altri strumenti come i redirect 301 e sitemap sempre aggiornate.
Canonical vs redirect 301: quando scegliere quale soluzione
La principale differenza fra queste due strategie riguarda l'esperienza dell’utente. Il canonical lascia accessibili tutte le varianti di URL, mentre il redirect 301 indirizza fisicamente il browser verso un altro indirizzo. Comprendere cos’è un URL canonico ti consente di mantenere accessibili più varianti, ma centralizzando l’indicizzazione su un’unica pagina.
Il tag canonical risulta particolarmente utile per gestire pagine con parametri di tracciamento, varianti di stampa o filtri di navigazione (ad esempio in e-commerce). Piattaforme evolute di ottimizzazione semantica sono in grado di implementare il tag canonical automaticamente, ottimizzando così la pagina in base all’intento di ricerca. Il redirect 301, invece, è più adatto per rimuovere definitivamente una pagina ormai obsoleta.
Questi due strumenti, seppur complementari, non devono essere confusi durante l’ottimizzazione tecnica. In particolare, per siti di e-commerce caratterizzati da numerosi filtri e parametri, il tag canonical rimane spesso la scelta migliore, permettendo di gestire tutte le variazioni della stessa pagina senza comprometterne l’usabilità.
Come il canonical consolida link juice e crawl budget
Quando più URL mostrano lo stesso contenuto, i backlink tendono a distribuirsi tra tutte queste varie versioni, indebolendo il potenziale di posizionamento di ciascuna. L’utilizzo del tag canonical consolida questa “forza” attorno a un unico URL preferito, indirizzando tutto il link juice verso la tua versione canonica. In questo modo, ogni link ricevuto andrà ad arricchire esclusivamente la tua pagina principale.
Sintassi HTML corretta per implementare il canonical tag
La struttura dell'attributo rel="canonical" è semplice, ma richiede attenzione ai dettagli per assicurare un corretto riconoscimento da parte dei motori di ricerca. Per una efficace canonicalizzazione, implementare questo tag richiede un codice preciso e l'uso di URL assoluti sempre coerenti.
Struttura del tag canonical nell'head: URL assoluti e HTTPS
Il canonical tag deve essere inserito nella sezione <head> della pagina HTML, idealmente subito dopo il tag title. L'attributo rel="canonical" indica chiaramente questa relazione specifica ai crawler, mentre l'attributo href definisce l'indirizzo assoluto della risorsa, includendo sempre il protocollo e il dominio.
- URL assoluto obbligatorio: Evita sempre percorsi relativi e usa indirizzi web completi per garantire che la versione canonica sia correttamente riconosciuta.
- Priorità HTTPS: Poiché Google privilegia gli URL sicuri, scegli sempre la versione HTTPS come canonica.
- Coerenza del dominio: Mantieni la stessa variante di dominio (con o senza www) in tutti i tuoi URL per evitare problemi di canonicalizzazione.
Ecco un esempio di codice corretto:
<head> <title>Prodotto X</title> <link rel="canonical" href="https://www.miosito.com/prodotto/x" /> </head>L'URL specificato deve corrispondere perfettamente alla risorsa che intendi indicizzare. Evita di utilizzare frammenti nell'attributo href, poiché questi vengono ignorati dai motori di ricerca.
Canonical auto-referenziale: quando e perché usarlo
La sintassi HTML canonical auto-referenziale fa sì che una pagina punti a sé stessa come versione preferita. Il codice viene inserito all'interno della stessa pagina di destinazione, confermando così a Google che l'URL attuale è quello definitivo e non un duplicato.
Questa strategia è consigliata per tutte le pagine del sito, anche quando non sono presenti duplicati evidenti. I professionisti SEO la considerano una buona pratica universale, poiché contribuisce a rimuovere ambiguità e garantisce un'architettura logica e coerente.
La pagina designata come canonica deve sempre includere un riferimento a sé stessa. Questo duplice riconoscimento consolida il processo di canonicalizzazione e guida correttamente gli spider nel loro lavoro di indicizzazione, assicurando che le tue versioni canoniche vengano scoperte e valorizzate.
Metodi di implementazione del canonical oltre l'HTML
L'implementazione del tag canonical non riguarda esclusivamente il codice HTML delle pagine web. Puoi utilizzare efficacemente gli header HTTP, la Sitemap XML e i redirect 301 per consolidare e dichiarare la versione canonica preferita di un contenuto. I motori di ricerca riconoscono e apprezzano questi segnali multipli molto più di quanto apprezzino un singolo tag isolato.
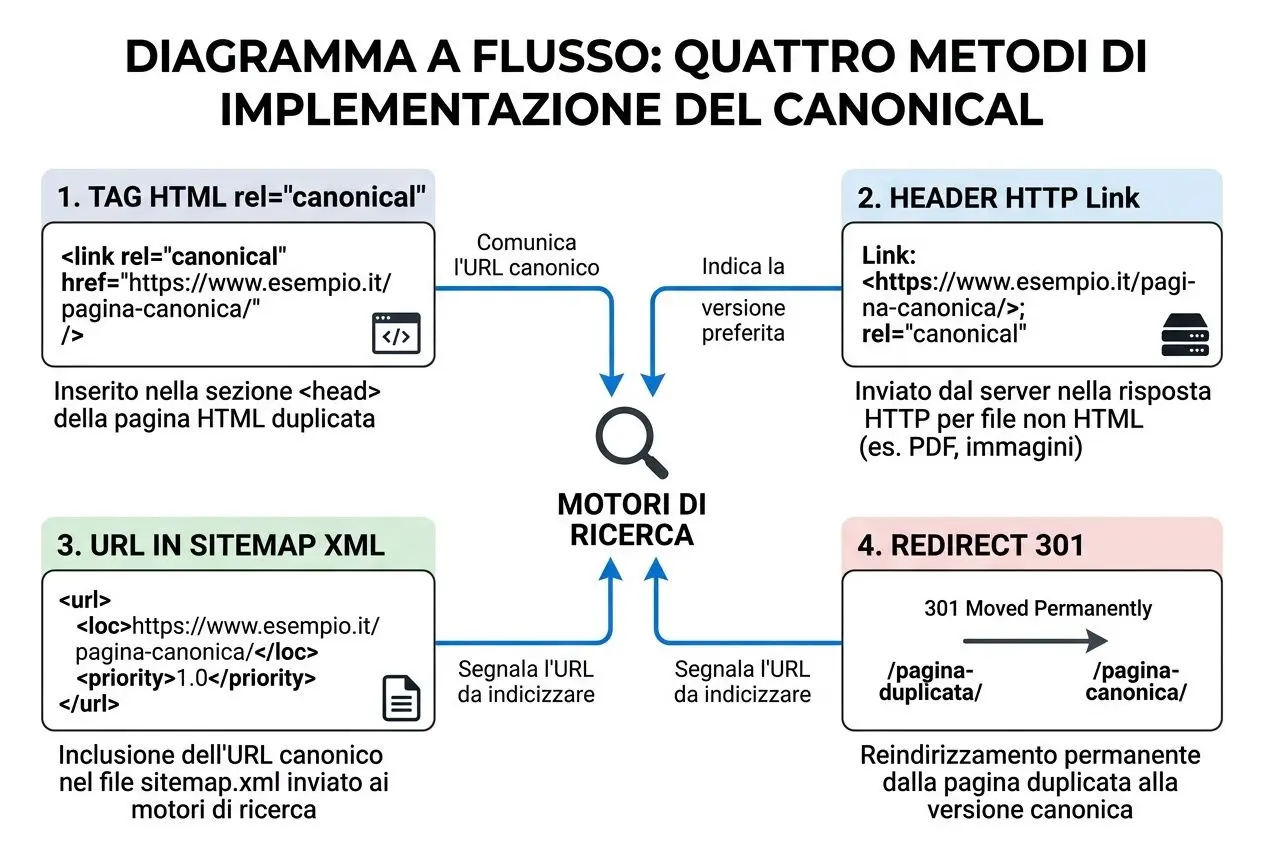
Header HTTP, Sitemap XML e redirect 301 per URL canonici
Per file specifici come i PDF, puoi inviare un apposito header direttamente dal tuo server web: Link: <https://www.miosito.com/documento-principale>; rel="canonical". Questa intestazione HTTP link comunica in modo inequivocabile l'URL canonico preferito al crawler. È una soluzione estremamente preziosa quando non hai la possibilità di modificare il codice HTML del file originale.
Inserire accuratamente gli URL canonici nella tua Sitemap XML fornisce un segnale complementare di grande utilità. Includendo esclusivamente gli URL che ritieni canonici, suggerisci a Google la versione specifica che dovrebbe essere indicizzata. Combina questa strategia con l'utilizzo del tag canonical per rafforzare il segnale e rendere la tua indicazione ancora più autorevole.
| Metodo | Quando utilizzarlo | Efficacia |
| Tag HTML rel="canonical" | Su tutte le pagine web standard | Alta, segnale facilmente riconoscibile |
| Header HTTP Link | Per PDF, immagini, risorse non HTML | Alta, specifico per risorse non-HTML |
| Sitemap XML | Come supporto aggiuntivo al tag HTML | Media-Alta, comunica l'intenzione |
| Redirect 301 | Per rimuovere definitivamente pagine duplicate e consolidare gli URL duplicati | Massima, trasferisce completamente l'autorità e l'autorevolezza dei link |
I redirect 301 permanenti rappresentano una scelta eccellente per consolidare definitivamente URL duplicati. Essi trasferiscono efficacemente l'autorità di ranking accumulata e reindirizzano sia gli utenti che i crawler alla versione preferita, eliminando l'URL duplicato originale. Al contrario, il tag canonical consente di mantenere accessibili entrambe le versioni per la navigazione, indicando semplicemente quale è la versione canonica.
Combinare più metodi per rafforzare il segnale canonico
La canonicalizzazione ideale si ottiene combinando più metodi di implementazione contemporaneamente per massimizzarne l'efficacia complessiva. Utilizza il tag rel="canonical" direttamente nell'HTML, sfrutta la segnalazione nella Sitemap XML e, quando possibile, imposta redirect 301 per unire tutte le pagine duplicate verso la stessa pagina canonica. Questo approccio a più livelli crea un segnale strutturato e coerente che i motori di ricerca difficilmente potranno ignorare.
Assicurati sempre che il tag canonical, la Sitemap e i redirect puntino tutti alla stessa identica versione preferita del contenuto. In questo modo comunicherai un'intenzione canonica inequivocabile, proteggendo attivamente la tua strategia SEO e riducendo il rischio che Google scelga autonomamente una risorsa canonica diversa.
Errori critici di canonicalizzazione da evitare
Errori nell'implementazione dei segnali canonici possono vanificare drasticamente i benefici di questa pratica fondamentale. Presta la massima attenzione ad ogni dettaglio tecnico ed esegui controlli regolari per garantire coerenza e correttezza dei segnali inviati ai motori di ricerca.
- Canonical su pagine 404: Evita assolutamente di puntare verso un URL che restituisce un errore 404. Il motore di ricerca potrebbe ignorare il segnale canonico, scegliendo autonomamente una versione alternativa dei tuoi contenuti.
- Catene di canonical: Evita di creare catene in cui la pagina A punta alla pagina B come canonica, e la pagina B punta alla pagina C. Ogni tag deve sempre puntare direttamente e solo all'URL finale canonico.
- Combinazione con noindex: Non inserire l'istruzione noindex (meta robot) sulla stessa pagina in cui specifichi un URL canonico. Sono segnali contraddittori che confondono gravemente i crawler: stai chiedendo di non indicizzare la pagina attuale ma allo stesso tempo stai anche dichiarando che essa stessa è la versione canonica.
- URL relativi nel canonical: Non utilizzare mai indirizzi relativi all'interno dell'attributo
hrefdel tag. Inserisci sempre URL assoluti completi, includendo il protocollo HTTPS e il dominio.
Non utilizzare mai file robots.txt per bloccare l'accesso alle versioni duplicate né lo Strumento di rimozione URL di Search Console come metodo per la canonicalizzazione. Questi strumenti servono a escludere le pagine dall'indice o a rimuoverlo temporaneamente, non a consolidarne il valore. Otterresti l'effetto opposto, compromettendo seriamente la visibilità organica del tuo sito web.
Verifica e monitoraggio del canonical tag con strumenti SEO
L'inserimento del canonical rappresenta solo il primo passo. È necessario un monitoraggio costante nel tempo per valutarne l'efficacia effettiva. Solo così potrai ottenere risultati concreti in termini di posizionamento.
Google Search Console per controllare URL canonici accettati
La verifica del tag canonical inizia sempre da Google Search Console. Attraverso lo strumento Ispezione URL, puoi verificare quale versione canonica viene effettivamente riconosciuta da Google. Digita l'indirizzo della pagina per confrontare le tue impostazioni con quelle interpretate dal motore di ricerca.
- URL Inspection Tool: ti consente di controllare il canonical dichiarato nel codice e confrontarlo con quello effettivamente validato da Google per quella specifica pagina.
- Rapporto di copertura (Coverage Report): analizza gli URL esclusi dall'indice, in particolare quelli segnalati come duplicati o contenuti duplicati non selezionati come primari.
- Esclusi dall'indice (Excluded): identifica i casi in cui Google ignora la tua indicazione canonica e sceglie autonomamente un'altra pagina come principale, segnalando potenziali conflitti.
Nella sezione Copertura di Google Search Console, puoi trovare queste risorse escluse. Questo accade quando il motore di ricerca seleziona autonomamente altre versioni canoniche che ritiene più appropriate, evidenziando un conflitto con altri fattori SEO.
Screaming Frog e Nox per il crawling del canonical
Screaming Frog è un crawler desktop molto conosciuto, perfetto per analizzare l'intero sito. Avviando una scansione (anche nella versione gratuita), puoi verificare la presenza di URL canonici corretti e unici. Il software segnala immediatamente se le impostazioni rispettano le regole fondamentali della SEO.
Nox, la piattaforma di Sedestral, esegue un'analisi tecnica automatica estremamente precisa. Rileva rapidamente tag canonical mancanti, configurati in modo errato o collegati a pagine inesistenti. Questo strumento aiuta a risolvere i conflitti per definire le versioni canoniche corrette e favorire il posizionamento organico.
Rémi: ottimizzazione automatica del canonical con l'IA
Rémi, l'intelligenza artificiale sviluppata da Sedestral, analizza automaticamente le pagine duplicate e suggerisce la configurazione ideale del canonical tag. Attraverso la funzione di ottimizzazione dei meta tag, inserisce automaticamente il canonical dove manca, permettendo ai motori di ricerca di identificare correttamente la versione canonica.
Questa tecnologia identifica velocemente tutti i contenuti duplicati presenti sul sito web. Il suo approccio automatizzato accelera notevolmente il processo di canonicalizzazione, riducendo al minimo gli errori manuali. Chi gestisce un e-commerce può così concentrarsi sulle vendite senza dover affrontare manualmente le complessità della SEO tecnica.