
Si le JavaScript améliore grandement l'expérience utilisateur, il représente un défi considérable pour le référencement. Vos applications peuvent afficher un contenu dynamique parfait, mais les moteurs de recherche ne l'indexent souvent que partiellement. Ce guide présente les bonnes pratiques SEO essentielles pour allier interactivité JavaScript, crawlabilité JavaScript et indexation de contenu dynamique, afin d'améliorer la visibilité de vos pages sans avoir à patienter des semaines.
Comment assurer la crawlabilité d'un site JavaScript
Bien que Googlebot interprète le JavaScript depuis 2015, d'autres crawlers comme Bingbot ou Yandex restent limités. Un rendu incomplet prive alors votre site d'une portion significative de trafic potentiel. Garantir une bonne crawlabilité JavaScript nécessite donc une stratégie précise et un rendu côté serveur fiable.
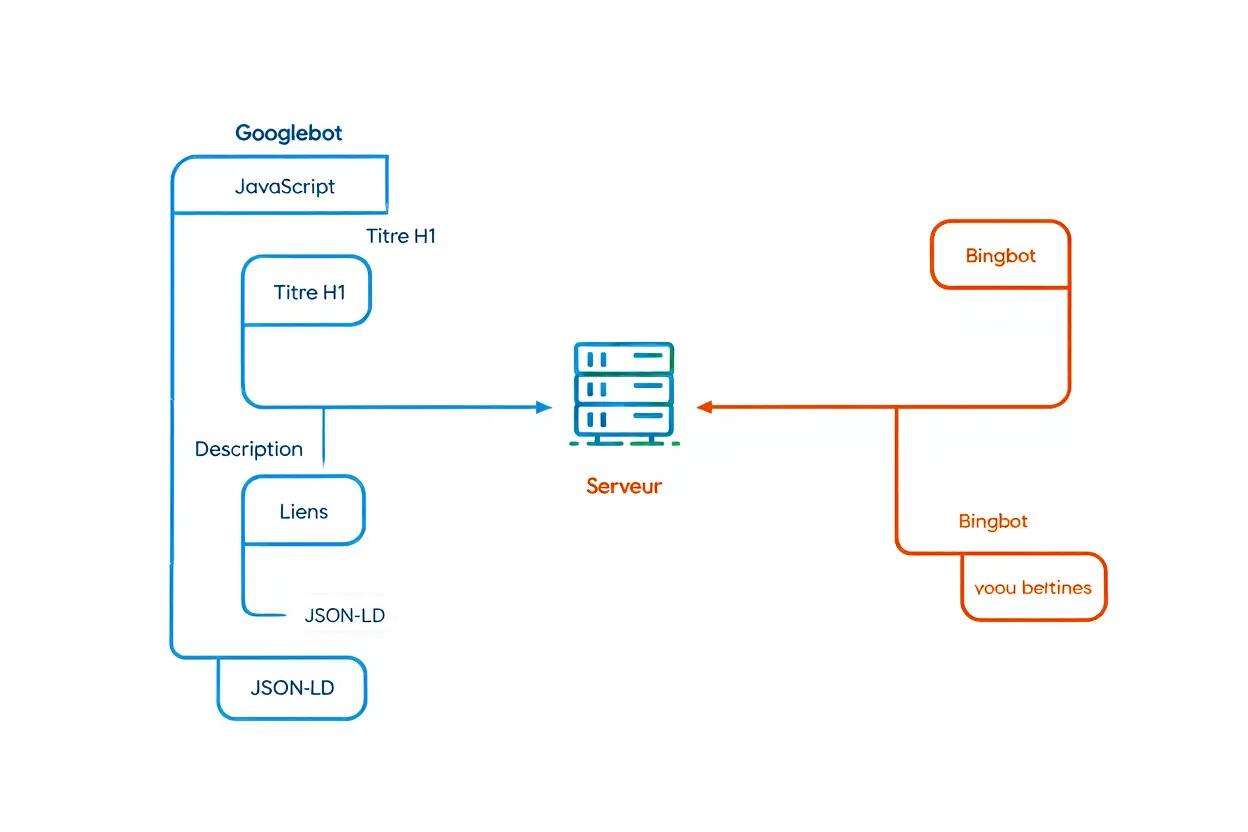
Garantir la présence du contenu dans le HTML initial
Les éléments critiques comme le H1, la méta-description, le texte principal et les liens internes doivent être inclus dans le HTML initial envoyé par le serveur, avant même l'exécution du code côté client. Tout contenu qui n'apparaît qu'après l'exécution du JavaScript reste invisible pour les crawlers incapables d'exécuter le DOM. Cette règle est fondamentale pour un référencement durable.
Privilégiez le rendu côté serveur (SSR) ou le pré-rendu statique. L'objectif est de produire un HTML sémantiquement riche, complet et parfaitement compréhensible sans JavaScript, en parfaite adéquation avec les bonnes pratiques SEO.
- Contenu critique en HTML : Les titres, le texte principal, les prix, les disponibilités et les appels à l'action doivent être présents dans le code source, et non injectés dynamiquement via JavaScript.
- Balises sémantiques : Structurez votre document en utilisant
<header>,<section>,<article>,<aside>et<footer>pour conserver un DOM clair, même si vous le modifiez ensuite. - Fallback noscript : Intégrez un résumé textuel essentiel dans une balise
<noscript>, incluant le titre, une description et le prix, pour les agents utilisateurs les plus restrictifs.
Un test simple consiste à exécuter la commande curl -L https://votresite.com et à vérifier que l'ensemble du contenu crucial s'affiche. S'il est absent de ce rendu, il le sera également lors de l'indexation.
Structurer les URLs et les liens pour les crawlers
Les liens générés via onclick ou window.location ne sont pas suivis, et les fragments d'URL (identifiés par le symbole #) sont généralement ignorés. Pour favoriser l'indexation de contenu dynamique, assurez-vous que chaque état d'une application monopage (SPA) possède sa propre URL, dépourvue de fragment superflu, et qu'il est accessible via de véritables liens internes de type <a href>.
Tirez parti de l'HTML5 History API (notamment pushState et replaceState) pour que chaque chemin, par exemple /produits/categorie/article, corresponde à une route serveur capable de délivrer un rendu complet.
- URLs sans fragments : Abandonnez le hash-bang (
#!) et optez pour des routes RESTful propres, directement indexables, comme/boutique/vetements/robe-rouge. - Balises rel="prev" et rel="next" : Pour gérer la pagination ou le défilement infini, indiquez explicitement la relation entre les pages à l'aide de ces méta-liens dans le
<head>ou via les en-têtes HTTP. - Redirections serveur : Utilisez de préférence des redirections HTTP 301 ou 302; évitez les redirections JavaScript qui ne transfèrent pas le PageRank.
Chaque URL doit être autonome et servir son HTML complet dès la requête initiale, sans dépendre d'un rendu JavaScript ultérieur.
Valider le rendu avec les outils de diagnostic
L'outil « Inspection d'URL » de la Search Console montre précisément ce que perçoit Googlebot après le rendu. Comparez le code source brut et le rendu final : si des disparités sont constatées, vous devrez optimiser votre stratégie de SSR ou de pré-rendu.
Testez également avec Screaming Frog en activant les modes « Crawl JavaScript » et « Text-only ». Pour finir, désactivez JavaScript dans votre navigateur pour vous mettre à la place d'un crawler. Ces vérifications régulières sont cruciales pour garantir une indexation optimale et une excellente crawlabilité JavaScript.
Quelle solution de rendu choisir pour le référencement
Le Server-Side Rendering, la génération statique et le rendu dynamique peuvent sembler complexes au premier abord. Pourtant, ces choix techniques impactent directement la visibilité et le référencement SEO de votre site. Chaque stratégie de rendu présente ses avantages, mais également des contraintes techniques ou budgétaires. Votre choix dépendra principalement du volume d'URL à gérer, de la fréquence des mises à jour de contenu et du budget d'infrastructure que vous pouvez allouer.
Comprendre les différences entre SSR, SSG et CSR
Le rendu côté serveur (SSR) génère des pages HTML complètes à chaque requête utilisateur, avant même l'exécution du JavaScript. La génération statique (SSG) compile ces mêmes pages HTML lors de la phase de build, puis les distribue directement via CDN. Le CSR, quant à lui, fournit une structure HTML minimale et laisse le navigateur construire l'intégralité du contenu, ce qui compromet sérieusement la crawlabilité et la visibilité SEO sans optimisations spécifiques.
- SSR (Next.js, Nuxt, Remix) : le serveur produit un rendu complet pour chaque visite, assurant un référencement optimal et une grande adaptabilité, mais la charge serveur reste importante.
- SSG (Astro, Next.js export statique) : les pages pré-générées sont diffusées sous forme de fichiers statiques ultra-performants, idéales pour les catalogues produits, même si un nouveau build s'impose dès qu'une modification intervient.
- CSR pur (Vue, React sans SSR, Angular) : un fichier HTML allégé parvient au client, puis le JavaScript assemble tout le rendu; sans pré-rendu, la visibilité SEO se trouve fortement affaiblie.
| Approche | Crawlabilité | Performance | Coût | Flexibilité |
| SSR | Excellente | Bonne (TTFB variable) | Moyen à élevé | Très élevée |
| SSG | Excellente | Excellente (CDN) | Faible | Modérée (rebuild lent) |
| CSR pur | Mauvaise | Moyenne (JS lourd) | Très faible | Excellente |
| Rendu dynamique | Excellente | Variable | Moyen | Bonne |
Un site e-commerce présentant un catalogue relativement stable, comme des vêtements ou des articles de décoration, bénéficie grandement d'un SSG complété par l'ISR pour actualiser uniquement les pages HTML modifiées. À l'inverse, une plateforme SaaS affichant du contenu utilisateur évoluant en temps réel tire davantage profit du SSR ou d'un rendu dynamique performant.
Implémenter le pré-rendu dynamique pour les bots
Le pré-rendu dynamique détecte l'User-Agent, puis transmet aux robots un rendu HTML généré via Puppeteer, Rendertron ou Prerender.io, tandis que les visiteurs humains accèdent à l'application SPA habituelle. Cette approche hybride combine la flexibilité du SSR, SSG, JavaScript avec un rendu HTML prêt à être indexé, améliorant ainsi le référencement sans nécessiter une refonte complète de l'architecture.
Assurez-vous que le serveur reconnaisse chaque URL comme un point d'entrée valide : https://monsite.com/produits/chemise-bleue doit retourner des pages HTML complètes et non une simple structure vide. Sans cela, les bots abandonnent rapidement et n'indexent qu'un fragment, compromettant la visibilité de votre contenu.
Optimiser l'hydratation progressive pour la performance
L'hydratation progressive, ou architecture islands, affiche d'abord le rendu côté serveur puis n'active que les composants interactifs essentiels via JavaScript. Vous diminuez ainsi le poids des scripts, boostez la performance et préservez un SEO optimal, tout en garantissant une expérience utilisateur fluide.
Optimiser les performances JavaScript pour le SEO
Un bundle JavaScript trop lourd ralentit le LCP, augmente le TBT et peut provoquer un CLS inattendu. Ces trois métriques Core Web Vitals, étroitement liées au JavaScript, influencent directement le classement SEO, car Google les juge essentielles.
Un rendu JavaScript trop lent complique également l'exploration : si le processus de rendu dépasse cinq secondes, le Googlebot interrompt l'opération. Le crawler indexe alors une version HTML incomplète, ce qui réduit sa visibilité et son autorité.
Réduire l'impact du JavaScript sur les Core Web Vitals
Chaque kilooctet économisé améliore la vitesse perçue : un bundle de 500 Ko retarde mécaniquement le LCP et prolonge le Time to Interactive. Maîtriser le poids de votre JavaScript reste donc vital pour vos positions dans la Search Console et les SERPs.
- Minification et tree-shaking : Supprimez le code mort avec Terser ou esbuild pour ne conserver que le code essentiel.
- Code-splitting : Séparez le bundle en plusieurs morceaux (chunks), chargez la partie critique en ligne ou via
preload, puis récupérez le reste en arrière-plan. - Compression Brotli : Plus efficace que gzip avec un gain de 20 à 30 %; activez-la côté serveur et sur votre CDN.
- Attributs defer/async : Tout script non critique placé dans le
<head>devrait utiliserdeferouasyncpour éviter de bloquer l'analyse initiale du HTML.
Testez régulièrement vos pages avec Lighthouse, WebPageTest et les rapports CrUX disponibles dans la Search Console. Intégrez ces audits dans votre pipeline CI/CD et empêchez la mise en production si le LCP dépasse 2,5 s ou si le FID excède 100 ms.
Implémenter le code-splitting et le lazy-loading efficacement
Chargez uniquement le JavaScript nécessaire à chaque vue : utilisez import() dynamique, React.lazy() ou Vue.defineAsyncComponent() pour différer le chargement des chunks secondaires. Vous pourrez ainsi réduire de 40 à 60 % le poids initial du bundle.
Pour les images, activez l’attribut natif loading="lazy" ou utilisez l'Intersection Observer. Sans cela, le Googlebot ne téléchargera pas les images situées hors de la fenêtre visible durant son exploration.
Concernant la pagination SEO et le infinite scroll, fournissez une URL distincte pour chaque segment (par exemple /produits?page=2), avec un contenu HTML entièrement rendu côté serveur. Ajoutez les balises rel="prev" et rel="next" dans le <head> ou via des en-têtes HTTP pour guider l'algorithme, éviter le contenu en double et préserver votre PageRank.
Intégrer les données structurées dans un site JavaScript
Les moteurs de recherche analysent le code HTML de votre site d'une manière différente de ce que perçoivent les utilisateurs. Pour bien comprendre votre contenu, ils s'appuient sur des données structurées JSON-LD, qui sont absolument essentielles pour le SEO. Il est crucial que ce balisage soit présent dans le rendu initial généré côté serveur, et non ajouté dynamiquement via du JavaScript après le chargement de la page.
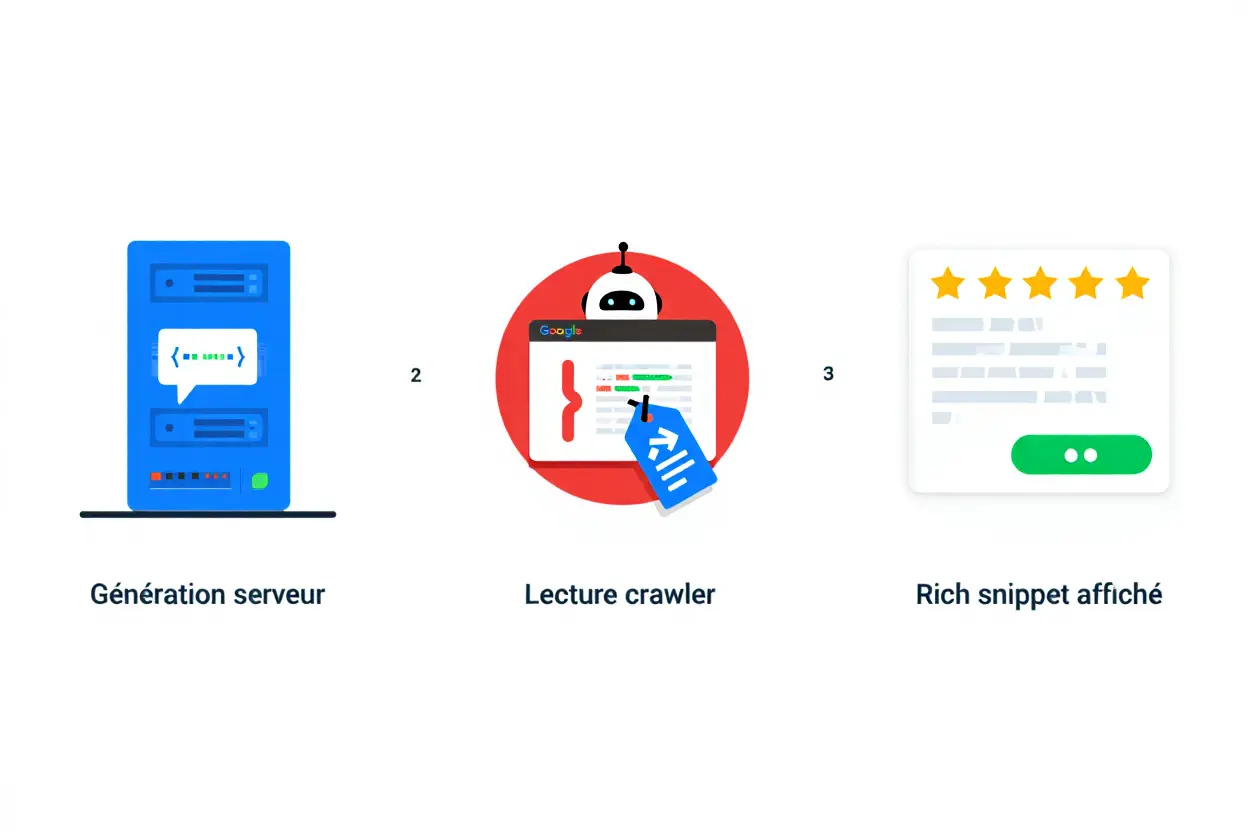
Générer le JSON-LD côté serveur pour les rich snippets
Le code JSON-LD doit être intégré directement dans le HTML source pour être détecté par tous les crawlers. Si vous l'insérez dynamiquement via du JavaScript, certains moteurs de recherche ignoreront ce contenu, ce qui fera disparaître vos rich snippets.
- JSON-LD côté serveur : Intégrez le script avant toute exécution de code client en utilisant un moteur de templates ou une solution de SSR (rendu côté serveur) comme Next.js ou Nuxt. Cela garantit un rendu solide et fiable.
- Schémas adaptés : Utilisez le schéma Product pour l'e-commerce, Article pour un blog, FAQPage pour une foire aux questions, ou LocalBusiness pour un commerce local.
- Cohérence stricte : Assurez-vous que les informations critiques comme le prix, la disponibilité ou les notes affichées sur la page correspondent parfaitement aux valeurs dans le JSON-LD, sans quoi vos rich snippets risquent d'être supprimés.
- Flux Google Merchant : Pour l'e-commerce, synchronisez le schéma Product généré côté serveur avec un flux de données actualisé pour éviter toute divergence.
Contrôlez chaque URL à l'aide d'outils comme le Rich Results Test et le Schema Markup Validator. Ils vous alerteront en cas de syntaxe incorrecte, de propriétés manquantes ou de types de schémas non supportés. Important : ne modifiez jamais les balises canoniques, les meta robots ou les descriptions via du JavaScript, car le DOM généré tardivement n'est souvent pas pris en compte par les moteurs de recherche.
Valider et maintenir la cohérence des données structurées
Une simple incohérence, comme un prix de 9,99 € dans le JSON-LD alors que la page affiche 14,99 €, peut vous faire perdre votre rich snippet. Ces balisages sont fragiles; testez systématiquement vos pages après chaque mise à jour.
- Rich Results Test : Saisissez l'URL de votre page pour confirmer que les extraits enrichis souhaités s'affichent correctement et sans erreur.
- Schema Markup Validator : Effectuez une analyse détaillée pour identifier les alertes et les incohérences potentielles.
- Search Console reports : Dans l'onglet « Améliorations » de la Search Console, surveillez les problèmes signalés pour vos Produits, Articles ou FAQ page par page.
- Tests automatisés : Intégrez une vérification du JSON-LD dans votre pipeline d'intégration continue (CI/CD) à l'aide d'outils comme Puppeteer ou un script Node.js, et bloquez le déploiement si le balisage échoue.
Pour un site e-commerce multilingue, générez également les balises hreflang lors du rendu côté serveur. Leur injection tardive via JavaScript reste souvent invisible pour de nombreux crawlers internationaux.
Automatiser la génération et les tests du balisage
Produire manuellement le JSON-LD pour chaque page prend énormément de temps et est propice aux erreurs. Automatisez cette tâche à l'aide d'un plugin pour votre CMS, d'un template en SSR, ou d'un script Node.js qui va directement chercher les informations dans votre base de données métier.
Intégrez la validation dans votre processus de déploiement : vérifiez la syntaxe JSON, les propriétés obligatoires et la cohérence avec le contenu affiché. Un déploiement devrait être bloqué dès qu'une erreur est détectée, vous évitant ainsi de passer plusieurs semaines sans rich snippets fonctionnels.
Auditer et maintenir la qualité du référencement JavaScript
Un audit de crawlabilité JavaScript n'est jamais une simple vérification ponctuelle. Il s'agit plutôt d'un processus continu d'amélioration. Chaque déploiement, chaque modification du bundle ou mise à jour des dépendances peut introduire des risques de régression, menaçant directement votre visibilité et votre référencement. Automatisez vos tests pour détecter les problèmes bien avant qu'ils n'affectent le rendu HTML et votre classement dans Google.
Configurer robots.txt et l'accès aux ressources critiques
Évitez de bloquer, dans votre fichier robots.txt, les répertoires contenant des fichiers JavaScript ou CSS essentiels (comme /static/, /assets/, /js/, /dist/). Si le Googlebot ne peut pas télécharger ces fichiers, le rendu restera incomplet et votre page ne s'affichera que partiellement, ce qui réduira sa visibilité.
- Vérification robots.txt : utilisez l'outil « Test robots.txt » de la Search Console pour confirmer que les ressources JavaScript critiques restent accessibles.
- Endpoints API : si votre rendu côté serveur ou votre pré-rendu dépend d'une API interne, assurez-vous que le Googlebot y a accès. Testez avec
curl -A "Googlebot" https://api.votresite.com/endpoint. - Compression et CDN : diffusez vos fichiers JS et CSS via un CDN (comme Cloudflare, Fastly ou AWS CloudFront) avec une compression Brotli ou Gzip et des en-têtes
Cache-Controlde longue durée, par exemplemax-age=31536000, immutablepour les bundles versionnés. - HTTP/2 multiplexing : activez HTTP/2 ou HTTP/3 pour paralléliser les requêtes de ressources critiques et réduire le temps perçu par le Googlebot (TTFB).
Servez ensuite les fichiers essentiels en utilisant les attributs preload ou modulepreload dans la balise <head>. Cela indique clairement au Googlebot quelles ressources doivent être traitées en priorité lors du rendu.
Gérer les scripts tiers et le lazy-loading du tracking
Les scripts tiers, qu'il s'agisse d'analytics, de chatbots, de widgets sociaux ou de vidéos intégrées, alourdissent souvent la page, ralentissent le rendu et dégradent les Core Web Vitals. Un audit de crawlabilité JavaScript doit examiner chaque service : est-il vraiment indispensable ? Peut-on le charger en arrière-plan pour préserver la crawlabilité JavaScript et la visibilité ?
Différez le chargement des balises marketing non essentielles (comme Facebook Pixel ou un Google Tag Manager lourd) jusqu'à l'interaction de l'utilisateur. En utilisant l'Intersection Observer ou des événements onclick, vous pouvez déclencher ces scripts après le consentement RGPD. Cela améliore la performance et le référencement sans sacrifier la collecte de données.
Automatiser les tests de crawlabilité et de performance
Les vérifications manuelles finissent toujours par être négligées, laissant passer des bugs en production. Intégrez des audits automatisés dans votre pipeline CI/CD pour garantir en permanence la crawlabilité JavaScript, la performance et un bon rendu côté serveur.
- Lighthouse API : exécutez Lighthouse à chaque commit pour surveiller les métriques LCP, FID et CLS, et bloquez le déploiement si les seuils ne sont pas respectés.
- Screaming Frog : utilisez le mode « Crawl JavaScript » puis « Text-only » pour identifier tout contenu invisible sans JS. Exécutez-le après chaque déploiement majeur.
- PageSpeed Insights API : comparez les métriques de laboratoire avec les données réelles CrUX pour comprendre les écarts entre vos tests et l'expérience utilisateur réelle.
- Rich Results Test API : validez le JSON-LD de chaque page indexée et recevez une alerte immédiate en cas d'erreur.
Exécutez curl -L https://votresite.com pour récupérer le HTML initial, puis comparez-le au rendu visible dans le navigateur à la même URL. Si certains éléments sont absents pour les bots, ils seront manquants dans l'index. Documentez ces écarts et priorisez les correctifs pour maintenir une excellente visibilité.