
Googlebot è il crawler principale di Google: esamina il tuo sito, raccoglie i contenuti e dà il via al processo di indicizzazione. In questo articolo scoprirai come funziona Googlebot, quali ostacoli tecnici ne limitano l'operatività e come ottimizzare le scansioni per aumentare la visibilità di un e-commerce o di un blog.
Cos'è Googlebot e come identifica le pagine web
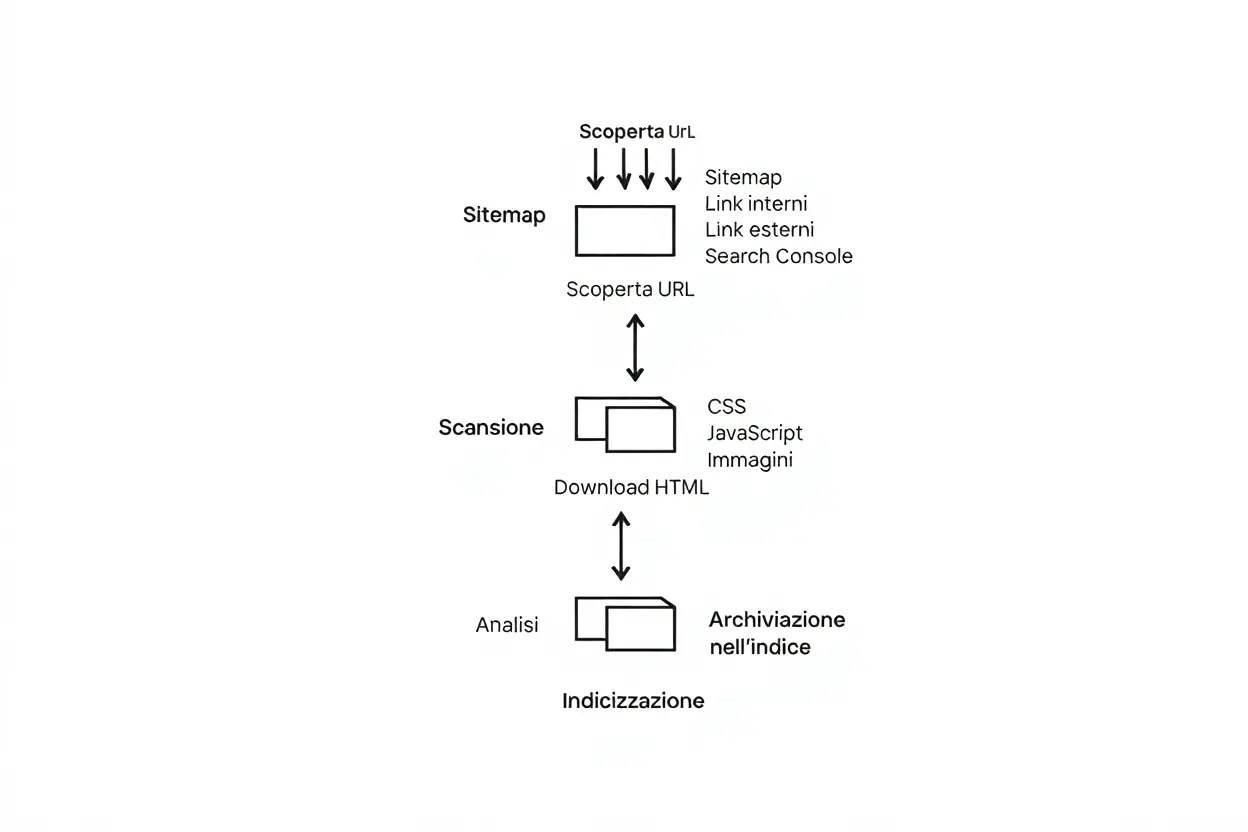
Cos'è Googlebot? È il web crawler che Google utilizza per esplorare Internet, individuare pagine web e acquisirne i contenuti. Durante il crawling, il crawler principale scopre gli URL attraverso link interni, esterni, sitemap o segnalazioni in Search Console, per poi scansionare HTML, immagini e script. Solo dopo questa fase fondamentale inizia l'indicizzazione, un momento cruciale poiché, senza scansioni, nessuna pagina può apparire nei risultati di ricerca.
Le due versioni del crawler: mobile e desktop
Il crawler Googlebot esiste in due versioni principali: Googlebot Smartphone e Googlebot Desktop, entrambe identificate dallo stesso token nel file robots.txt. Oltre l'80% delle scansioni proviene da Googlebot Smartphone, mentre il bot desktop genera la parte rimanente del traffico. Per riconoscerle, è sufficiente analizzare l'header user-agent che accompagna ogni richiesta HTTP inviata al tuo sito.
- Googlebot Smartphone: simula un browser mobile ed è responsabile della maggior parte delle scansioni, seguendo il paradigma dell'indicizzazione mobile-first.
- Googlebot Desktop: emula un browser desktop tradizionale e interviene principalmente quando manca una versione mobile o il layout non è responsive.
- Identificazione User-Agent: la stringa user-agent (ad esempio, "Googlebot/2.1; +http://www.google.com/bot.html") consente di identificare quale spider sta scansionando il tuo sito.
Dopo il passaggio all'indicizzazione mobile-first, Google determina il ranking considerando principalmente la versione mobile. Una versione lenta o incompleta può ridurre il crawl budget per dispositivi mobili e compromettere la visibilità complessiva del sito.
Come verificare l'autenticità delle richieste Googlebot
Affidarsi esclusivamente all'user-agent può essere rischioso, poiché bot malevoli potrebbero spacciarsi per Googlebot. Per validare una richiesta, è necessario eseguire un reverse DNS lookup sull'indirizzo IP e confrontarlo con gli intervalli ufficiali pubblicati da Google. Se l’indirizzo non corrisponde, quella specifica scansione del sito web non proviene dal crawler ufficiale.
La maggior parte delle richieste legittime proviene da IP con sede negli Stati Uniti, quindi i picchi di attività si verificano generalmente durante l'orario lavorativo del fuso del Pacifico. Utilizza strumenti gratuiti per il reverse DNS e consulta la documentazione ufficiale di Google per verificare gli IP autorizzati dei crawler.
Limiti tecnici di scansione e rendering
Googlebot si avvale di un motore di rendering Chromium aggiornato, che esegue JavaScript e costruisce il modello della pagina in circa cinque secondi. Se il rendering fallisce, i contenuti generati dinamicamente non vengono presi in considerazione durante l'indicizzazione, con ripercussioni negative dirette sul posizionamento.
Esistono anche limiti di dimensione rigidi: vengono indicizzati solo i primi 2 MB di codice HTML, CSS o JavaScript, e i primi 15 MB di un file PDF. Qualsiasi contenuto oltre queste soglie viene ignorato senza preavviso, riducendo significativamente la copertura nelle ricerche.
Librerie JavaScript corrotte, timeout o dipendenze mancanti possono impedire la corretta visualizzazione nel browser interno di Googlebot, ritardando o addirittura bloccando l'indicizzazione dei contenuti. Testare regolarmente il rendering rimane quindi una priorità assoluta nella strategia SEO di ogni sito.
Crawl budget: come Google distribuisce le risorse sul tuo sito
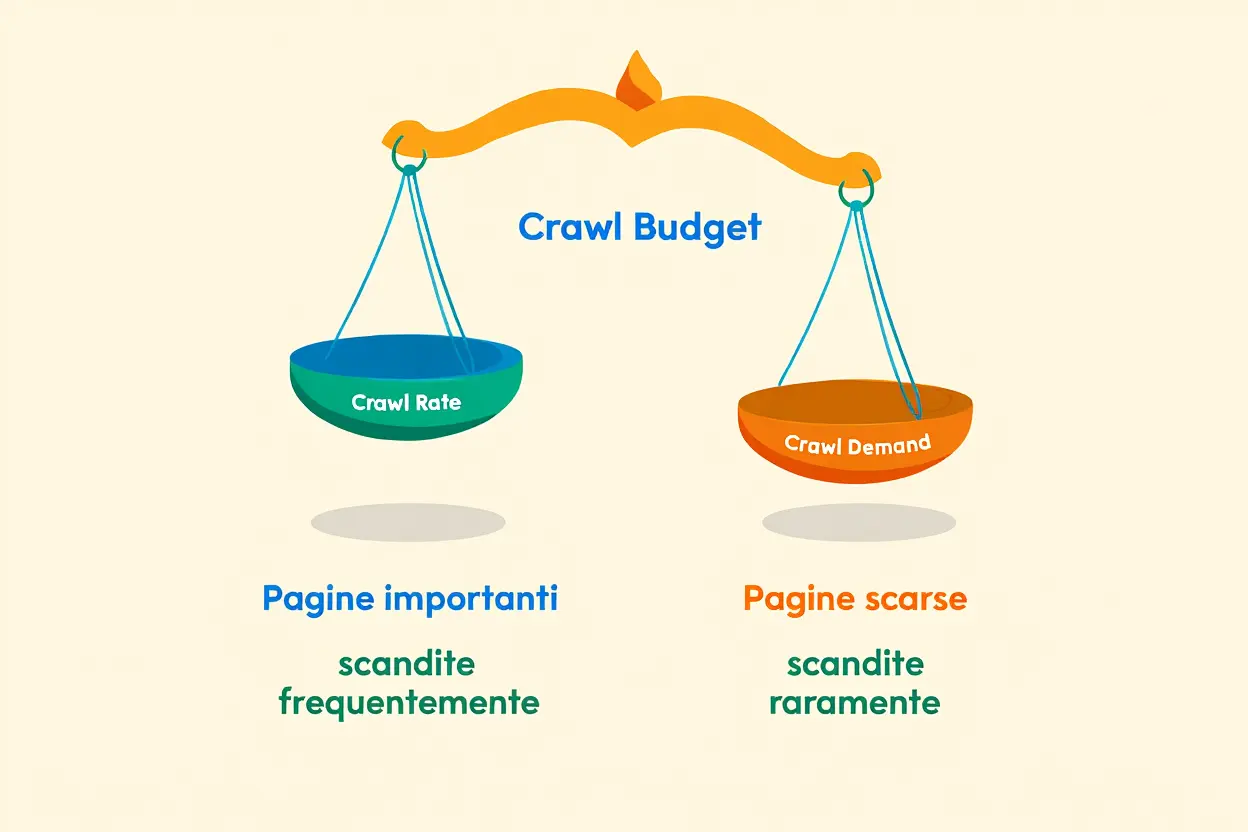
Il crawl budget è il numero di pagine che Googlebot può e vuole scansionare sul tuo sito in un determinato lasso di tempo. Non si tratta di una risorsa infinita, ma deriva dall’interazione tra il crawl rate (la velocità tollerata dal tuo server) e il crawl demand (la frequenza degli aggiornamenti e l’autorevolezza del sito). Trascurare l'ottimizzazione del crawl budget significa rischiare che Googlebot perda tempo a scansionare contenuti poco utili, invece di dedicarsi alle pagine più strategiche, sprecando così risorse preziose.
Crawl rate e crawl demand: i fattori chiave
Comprendere la differenza tra crawling e indicizzazione è fondamentale per una corretta valutazione del crawl budget del tuo progetto. Durante il crawling, il crawler scopre e scarica le pagine, mentre l'indicizzazione consiste nell'analizzare quei contenuti per inserirli nell'indice di Google. In pratica, Googlebot potrebbe scansionare un URL senza poi indicizzarlo (se trova un meta tag noindex) oppure indicizzare un contenuto che viene scansionato di rado (se è bloccato da robots.txt ma viene linkato da altri siti).
- Crawl rate: La velocità massima con cui Googlebot può scansionare il tuo sito senza sovraccaricarlo. Dipende principalmente dalla velocità di risposta del server e dalla capacità della banda disponibile.
- Crawl demand: Quanto spesso Google desidera scansionare il tuo sito. Questo valore si basa sulla frequenza degli aggiornamenti, sull'autorità del dominio, sulla qualità dei backlink e dei contenuti. I siti aggiornati frequentemente e con molti backlink di qualità ricevono scansioni più assidue.
- Interazione dei due fattori: Il crawl budget finale è determinato dal valore minore tra il crawl rate consentito e il crawl demand desiderato. Un server lento limiterà le scansioni, ma anche un server veloce con contenuti di bassa qualità avrà un budget limitato.
Le pagine che vengono aggiornate spesso o che sono supportate da numerosi backlink ricevono scansioni più regolari rispetto ai contenuti statici. Se pubblichi un articolo sul blog una volta al mese, Googlebot lo scansionerà meno di una scheda prodotto che viene rivista ogni giorno. Questo meccanismo permette a Google di dedicare il proprio crawl budget ai contenuti che cambiano realmente e che sono più rilevanti per gli utenti.
| Tipo di contenuto | Frequenza di crawl tipica | Fattori che aumentano il crawl |
| Homepage | Giornaliera o più volte al giorno | Autorità, link interni frequenti, alta importanza |
| Pagina di prodotto (e-commerce) | Settimanale o giornaliera | Aggiornamenti di prezzo, disponibilità, backlink |
| Articolo blog pubblicato | Settimanale, poi mensile | Freschezza, condivisioni, link da siti autorevoli |
| Pagina statica interna | Mensile o meno | Link interni strategici, aggiornamenti contenuto |
Differenza tra crawling e indicizzazione del sito
Molti professionisti confondono ancora il crawling e l'indicizzazione, che invece sono due fasi distinte e indipendenti del processo di scansione. Un'efficace ottimizzazione del crawl budget nasce proprio da questa distinzione, perché ti permette di indirizzare il crawler verso le pagine che desideri veramente far indicizzare. Il fatto che Googlebot scansiona un URL non garantisce che questo verrà automaticamente inserito nell'indice: alcuni contenuti possono essere esclusi a causa di tag noindex o altre direttive.
Il processo di scansione inizia da sitemap, link interni, collegamenti esterni e richieste inviate tramite Search Console, che insieme creano la coda degli URL da scansionare. Nella fase successiva di indicizzazione, Google analizza il contenuto scaricato e decide se indicizzare o meno ciascuna pagina. Un uso accorto del file robots.txt, dei tag canonical e della gestione dei parametri URL aiuta a evitare scansioni superflue, liberando così crawl budget per contenuti più utili e riducendo il rischio di duplicati. Quando blocchi pagine ridondanti nel robots.txt, Googlebot non le scansiona e il budget viene dirottato verso le sezioni realmente importanti del sito.
Gestire l'accesso di Googlebot: robots.txt e direttive
Il file robots.txt e i meta tag sono strumenti essenziali per definire quali contenuti Googlebot può scansionare e indicizzare. Una configurazione accurata di queste direttive impedisce al crawler di sprecare crawl budget su pagine senza valore strategico, assicurando al tuo sito la massima visibilità per le sezioni più importanti.

Come usare robots.txt, meta tag e header HTTP
Posizionato nella radice del dominio, il file robots.txt controlla l'accesso di ogni crawler attraverso le direttive Allow e Disallow. Nota bene: non puoi applicare regole diverse per Googlebot desktop e mobile, poiché le direttive valgono per entrambi. Quando Googlebot scansiona un URL bloccato, interrompe immediatamente la visita, risparmiando crawl budget per i contenuti prioritari del tuo sito.
- Robots.txt blocca la scansione: La direttiva Disallow impedisce la visita e riduce gli sprechi, risultando utile per risorse prive di valore SEO.
- Meta tag robots consente la scansione ma ferma l'indicizzazione: <meta name="robots" content="noindex, nofollow"> permette al crawler di scansionare la pagina senza aggiungerla all'indice.
- Header X-Robots-Tag per file non HTML: L'header “X-Robots-Tag: noindex” applica la stessa logica a file come PDF, immagini o video che non dispongono di un tag head HTML.
- Canonical tag concentra l'autorità: <link rel="canonical"> segnala a Google la versione preferita di una pagina, evitando duplicati e ottimizzando il crawl budget.
Per bloccare sia la scansione che l'indicizzazione, è consigliabile combinare il file robots.txt con un meta tag noindex. Usare solo il robots.txt potrebbe non essere sufficiente, poiché Google potrebbe comunque creare un riferimento se la pagina viene linkata da altri siti. Al contrario, usare solo il meta tag noindex comporta che Googlebot scansioni la pagina inutilmente, consumando risorse preziose.
Verificare e correggere errori di crawl in Search Console
Google Search Console offre i report Coverage e Crawl Stats, che mostrano quante richieste Googlebot effettua sul tuo sito, quali URL vengono indicizzati e dove si presentano eventuali problemi. Con l'URL Inspection Tool puoi confrontare l'HTML recuperato con il rendering finale, verificare errori di crawl e assicurarti che il meta tag robots e le altre direttive funzionino correttamente.
Tra gli errori più comuni vi sono i codici 404, 500, timeout e redirect errati, ciascuno dei quali consuma crawl budget senza offrire alcun beneficio. Analizza regolarmente i log del server con strumenti come Screaming Frog o ELK, rimuovi gli URL non validi dalla sitemap e ottimizza la velocità del server per prevenire ulteriori sprechi.
Problemi di rendering JavaScript e loro impatto
Durante la fase di rendering, Googlebot ha a disposizione solo pochi secondi; script lenti o interrotti possono rendere le pagine vuote, compromettendo l'indicizzazione dei tuoi contenuti. Nei siti basati su React, Vue o Angular, assicurati che gli elementi essenziali siano visibili prima del timeout, in modo che il crawler possa rilevarli immediatamente.
Errori nelle librerie JavaScript, API irraggiungibili o dipendenze mancanti possono impedire a Googlebot di visualizzare il contenuto dinamico. Utilizza il Web Rendering Service o simula il browser di Googlebot per confrontare l'HTML recuperato con quello renderizzato, correggi il codice e monitora il report Coverage per verificare errori di crawl risolti.
Ottimizzare il sito per migliorare la scansione Google
Ora che hai capito come funziona Googlebot, puoi ottimizzare il tuo sito per una scansione più rapida ed efficiente. Sebbene i sistemi automatizzino gran parte del lavoro, comprendere ciò che avviene dietro le quinte ti permette di mantenere il controllo e intervenire quando necessario.
Strategie per aumentare il crawl budget disponibile
Aumentare il crawl budget significa convincere Google che il tuo sito merita di essere scansionato più spesso e in profondità. Un audit indicizzazione sito può rivelare quali URL inutili assorbono risorse, permettendoti di concentrare Googlebot smartphone sui contenuti più importanti.
- Contenuti di qualità: Articoli ben scritti, schede prodotto dettagliate e guide approfondite segnalano al crawler che il sito offre valore, incentivando scansioni più frequenti.
- Tag canonical: Utilizza il tag canonical per unire le varianti duplicate di una pagina. In questo modo riduci le scansioni ridondanti e preservi il crawl budget per URL più rilevanti.
- Link interni chiari: Una struttura logica (homepage → categorie → pagine interne) guida Google durante la scansione e favorisce una corretta indicizzazione.
- Redirect minimi: Cerca di limitare le catene di reindirizzamento (301/302) a un solo salto. Ogni redirect consuma risorse di scansione e rallenta il rendering.
Aggiorna regolarmente la sitemap, rimuovendo gli URL obsoleti. Un file ordinato aiuta Google a distribuire meglio il crawl budget. Monitora i log del server: se noti che il crawler sta scansionando pagine di ricerca interne o pagine di ringraziamento, bloccale tramite robots.txt per evitarne lo spreco.
Audit tecnico per identificare problemi di indicizzazione
Un audit tecnico approfondito è alla base di una solida ottimizzazione SEO crawler: verifica la velocità del server, gli errori JavaScript, i problemi di rendering e i contenuti duplicati che potrebbero rallentare la scansione. Un sito veloce, stabile e coerente favorisce un'esperienza di crawler più fluida e una migliore indicizzazione.
Controlla settimanalmente il report Copertura in Search Console. Se noti un calo improvviso delle pagine indicizzate, agisci tempestivamente. Usa lo strumento Ispezione URL per assicurarti che il contenuto venga renderizzato correttamente e risolvi eventuali anomalie prima che il crawl budget venga sprecato.
Mobile-First Index: ottimizzare la versione mobile
Con l’avvento del Mobile-First Index, Googlebot smartphone gestisce oltre l'80% delle scansioni. Una versione mobile lenta o incompleta riduce il crawl budget e influisce negativamente sul posizionamento. Assicurati che contenuti, immagini e markup siano identici alla versione desktop per permettere a Google di indicizzare senza intoppi.
Prova il sito su dispositivi reali e con connessioni 4G: se il caricamento supera i tre secondi, ottimizza immagini, script e meccanismi di caching. Migliorare i Core Web Vitals (LCP, FID, CLS) non solo eleva l’esperienza utente, ma incoraggia Google a scansionare il tuo contenuto più spesso e in maggiore profondità.